C.1 Notation
I shall assume that we have some function 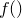 , which takes
, which takes 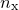 parameters,
parameters, 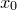 ...
...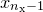 , the set of which may collectively be written as the vector
, the set of which may collectively be written as the vector  . We are supplied a datafile, containing a number
. We are supplied a datafile, containing a number 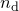 of datapoints, each consisting of a set of values for each of the parameters, and one for the value which we are seeking to make
of datapoints, each consisting of a set of values for each of the parameters, and one for the value which we are seeking to make 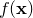 match. I shall call of parameter values for the
match. I shall call of parameter values for the 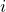 th datapoint
th datapoint 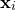 , and the corresponding value which we are trying to match
, and the corresponding value which we are trying to match 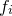 . The data file may contain error estimates for the values , which I shall denote
. The data file may contain error estimates for the values , which I shall denote 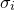 . If these are not supplied, then I shall consider these quantities to be unknown, and equal to some constant
. If these are not supplied, then I shall consider these quantities to be unknown, and equal to some constant 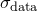 .
.
Finally, I assume that there are 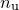 coefficients within the function that we are able to vary, corresponding to those variable names listed after the via statement in the fit command. I shall call these coefficients
coefficients within the function that we are able to vary, corresponding to those variable names listed after the via statement in the fit command. I shall call these coefficients 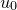 ...
...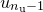 , and refer to them collectively as
, and refer to them collectively as  .
.
I model the values in the supplied data file as being noisy Gaussian-distributed observations of the true function , and within this framework, seek to find that vector of values which is most probable, given these observations. The probability of any given is written 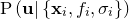 .
.