C.3 Estimating the error in 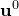
To estimate the error in the best-fitting parameter values that we find, we assume 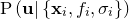 to be approximated by an
to be approximated by an 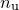 -dimensional Gaussian distribution around . Taking a Taylor expansion of
-dimensional Gaussian distribution around . Taking a Taylor expansion of 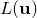 about , we can write:
about , we can write:
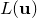 |
 |
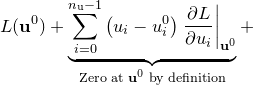 |
(C.4) | ||
 |
|
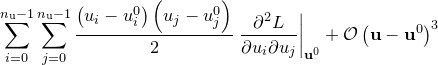 |
Since the logarithm of a Gaussian distribution is a parabola, the quadratic terms in the above expansion encode the Gaussian component of the probability distribution about .1 We may write the sum of these terms, which we denote 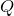 , in matrix form:
, in matrix form:
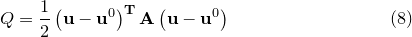 |
(C.5) |
where the superscript 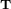 represents the transpose of the vector displacement from , and
represents the transpose of the vector displacement from , and 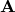 is the Hessian matrix of
is the Hessian matrix of  , given by:
, given by:
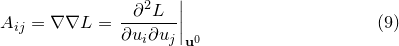 |
(C.6) |
This is the Hessian matrix which is output by the fit command. In general, an -dimensional Gaussian distribution such as that given by Equation () yields elliptical contours of equi-probability in parameter space, whose principal axes need not be aligned with our chosen coordinate axes – the variables 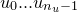 . The eigenvectors
. The eigenvectors  of are the principal axes of these ellipses, and the corresponding eigenvalues
of are the principal axes of these ellipses, and the corresponding eigenvalues 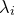 equal
equal 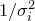 , where
, where 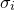 is the standard deviation of the probability density function along the direction of these axes.
is the standard deviation of the probability density function along the direction of these axes.
This can be visualised by imagining that we diagonalise , and expand Equation () in our diagonal basis. The resulting expression for is a sum of square terms; the cross terms vanish in this basis by definition. The equations of the equi-probability contours become the equations of ellipses:
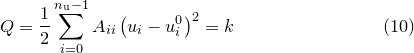 |
(C.7) |
where 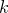 is some constant. By comparison with the equation for the logarithm of a Gaussian distribution, we can associate
is some constant. By comparison with the equation for the logarithm of a Gaussian distribution, we can associate 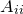 with
with 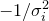 in our eigenvector basis.
in our eigenvector basis.
The problem of evaluating the standard deviations of our variables 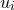 is more complicated, however, as we are attempting to evaluate the width of these elliptical equi-probability contours in directions which are, in general, not aligned with their principal axes. To achieve this, we first convert our Hessian matrix into a covariance matrix.
is more complicated, however, as we are attempting to evaluate the width of these elliptical equi-probability contours in directions which are, in general, not aligned with their principal axes. To achieve this, we first convert our Hessian matrix into a covariance matrix.
Footnotes
- The use of this is called Gauss’ Method. Higher order terms in the expansion represent any non-Gaussianity in the probability distribution, which we neglect. See MacKay, D.J.C., Information Theory, Inference and Learning Algorithms, CUP (2003).